library(dplyr)
library(ggplot2)
library(palmerpenguins)Soluciones capítulo 1
Actividad 1
Abre colorbrewer y elige una paleta de colores para representar estos tres gráficos sobre el mapa que muestran de ejemplo. Para elegir una correcta, piensa en la naturaleza de los datos (secuenciales, divergentes o cualitativos):
- El nivel de contaminación por región: secuencial
- Cambio relativo en el número de habitantes con respecto a la última decada (p.e. -5%, +10%, …): divergente
- La etnia predominante por región: cualitativa
Actividad 2
Examina el dataset diamonds, incluido dentro de la librería de ggplot2. Consulta la ayuda con ?diamonds y examina su contenido.
Pinta la relación en un gráfico de puntos del precio frente a los quilates.
# opcional, toco el alpha (opacidad) para que se vean mejor los puntos superpuestos
ggplot(diamonds, aes(x = carat, y = price)) +
geom_point(alpha = 0.2)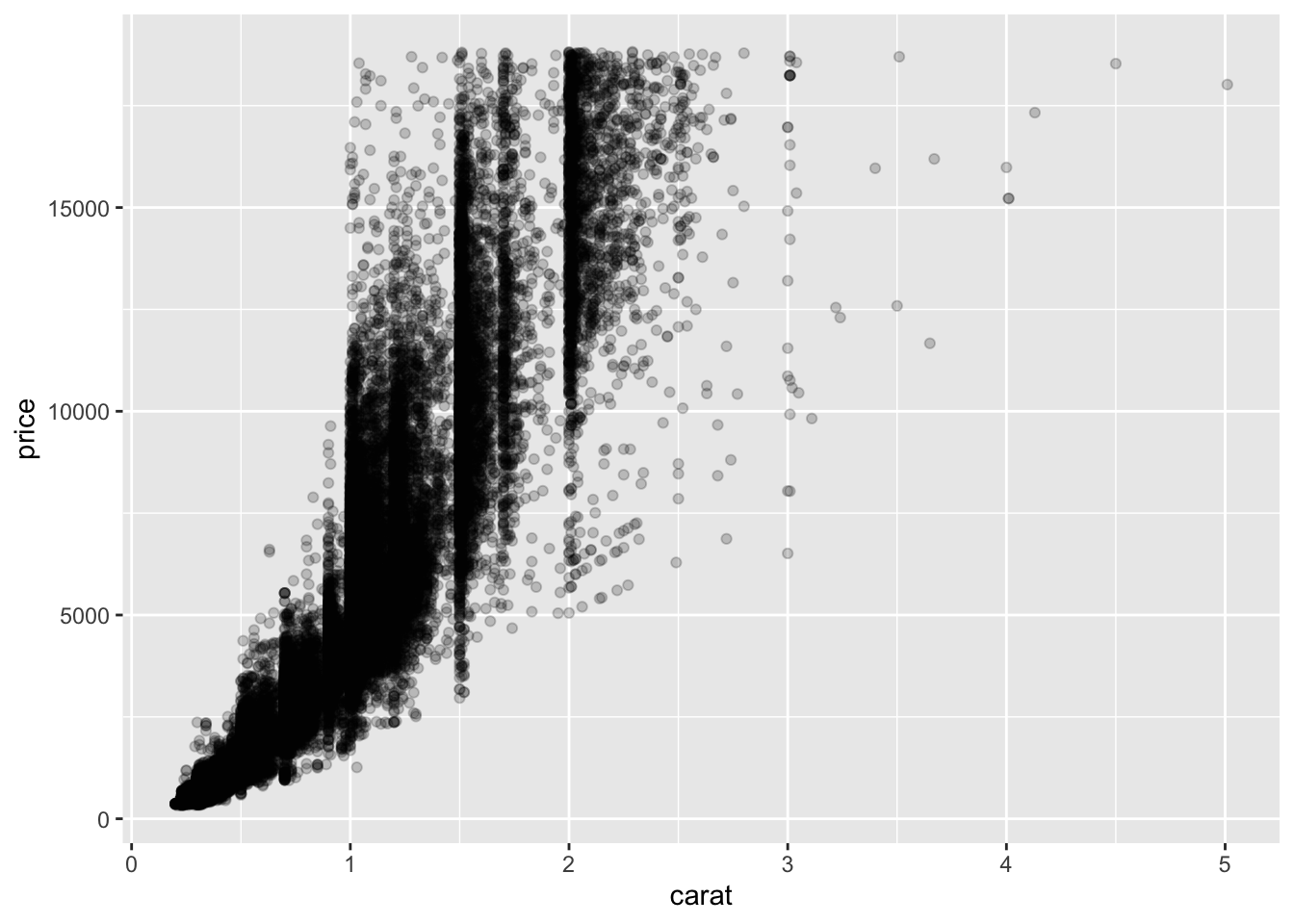
Actividad 3
Con el dataset penguins:
- Pinta la relación entre longitud y profundidad del pico (bill).
ggplot(data = penguins) +
geom_point(mapping = aes(x = bill_length_mm, y = bill_depth_mm))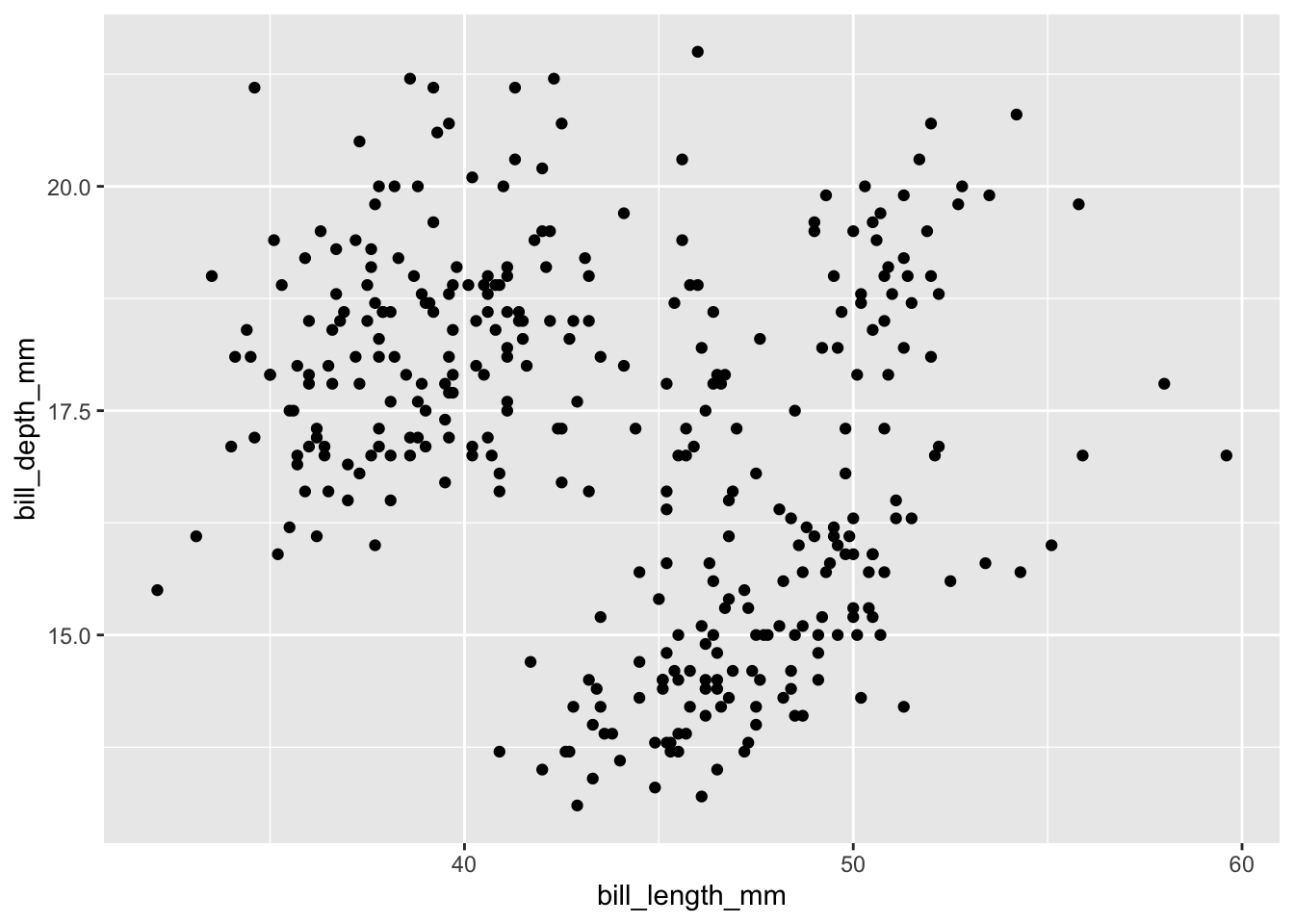
- Añade al gráfico del punto 1 la distinción entre especies mediante el color.
ggplot(data = penguins) +
geom_point(mapping = aes(x = bill_length_mm, y = bill_depth_mm, color = species))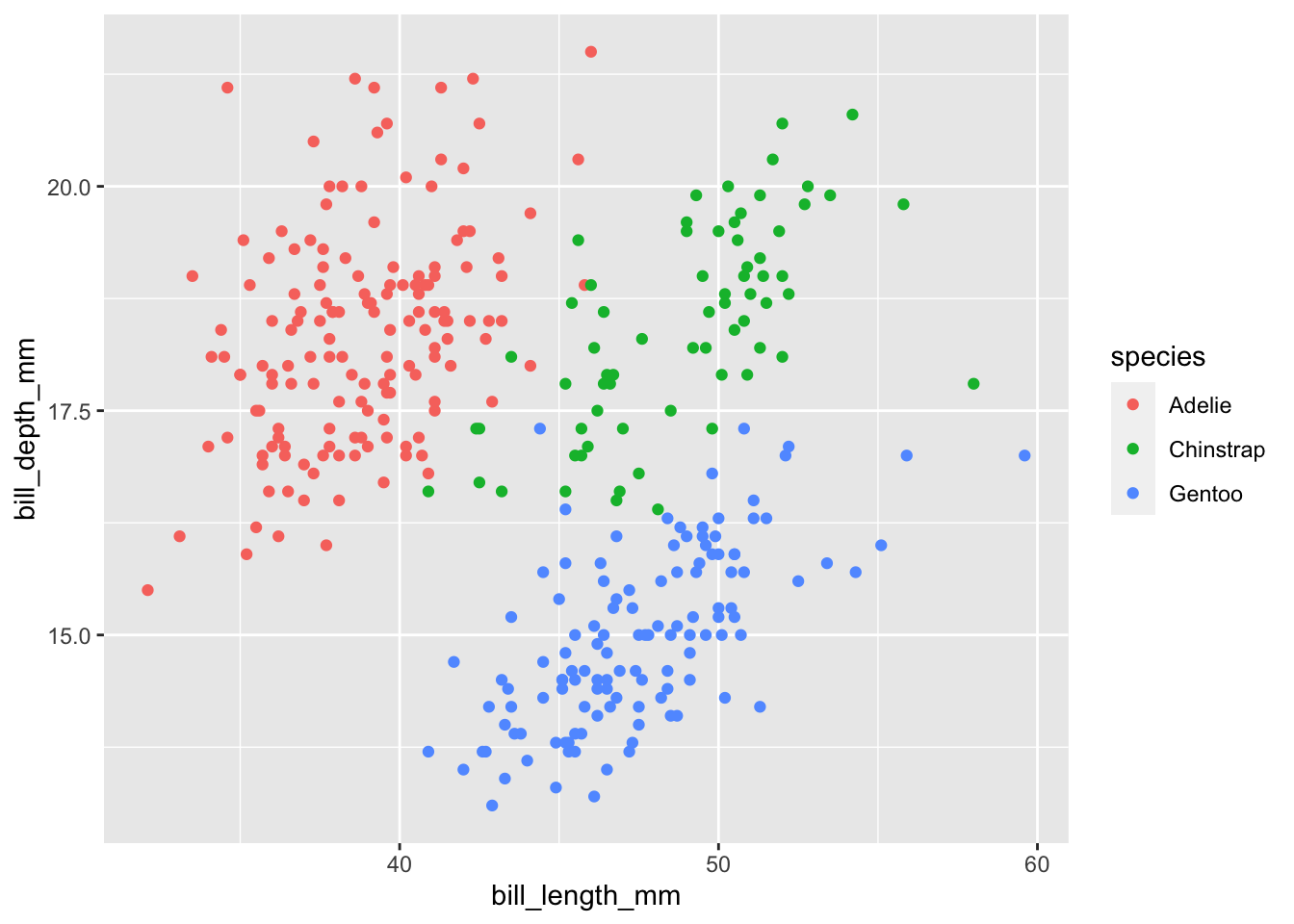
- Añade al gráfico del punto 1 la distinción entre el peso corporal mediante el color.
ggplot(data = penguins) +
geom_point(mapping = aes(x = bill_length_mm, y = bill_depth_mm, color = body_mass_g))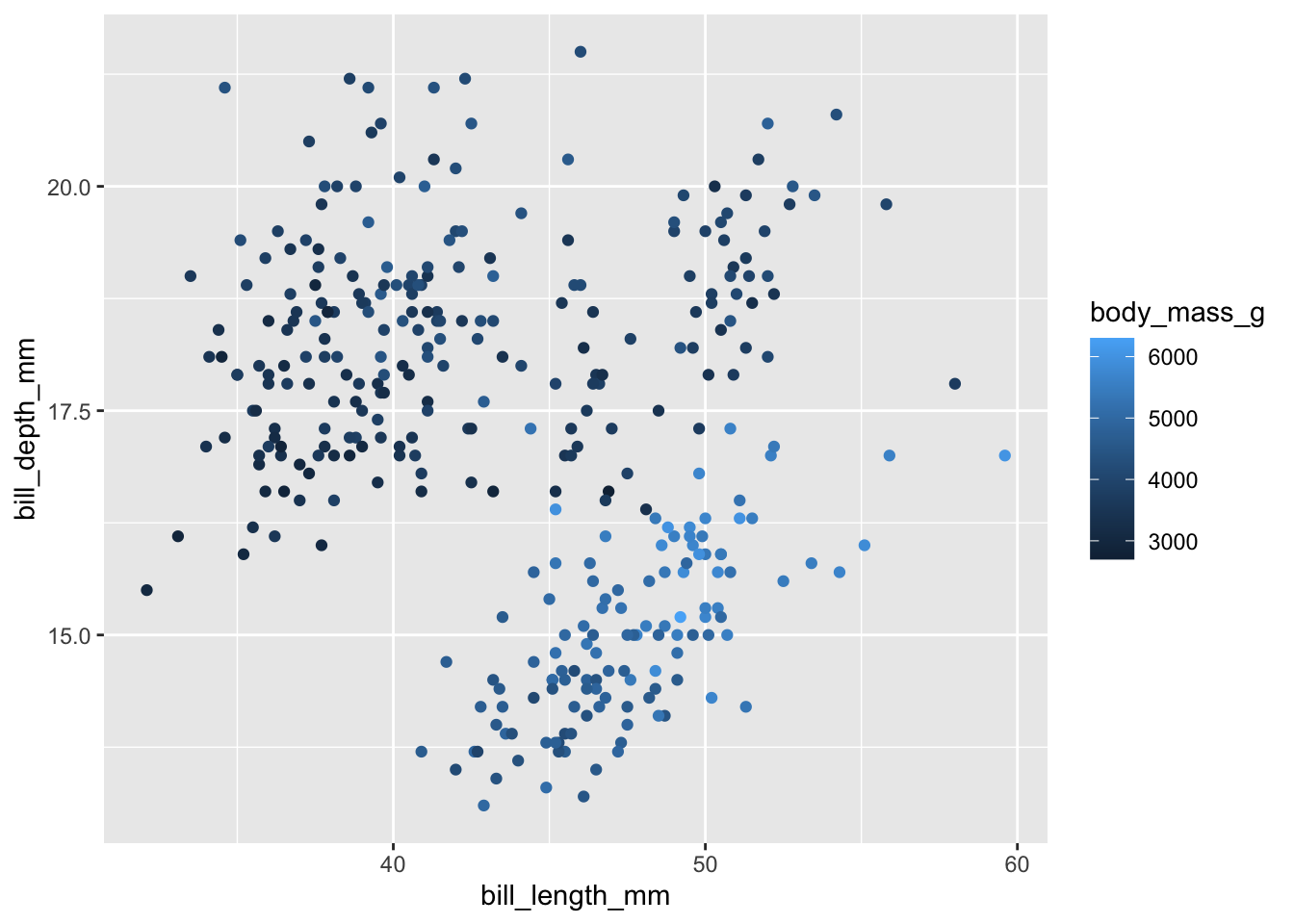
- ¿Qué observas en las escalas de color que ha utilizado ggplot en cada uno de los dos casos? ¿De qué naturaleza (secuencial, divergente o cualitativa) es cada una de ellas? ¿Por qué crees que ha hecho esto por defecto?
Respuesta: para species se utiliza una escala cualitativa, para body_mass_g se utiliza una secuencial. Es por el tipo de dato: para datos factor / cadenas de caracters / booleanos, ggplot utiliza por defecto escalas cualitativas. Para numéricos, ggplot utiliza escalas secuenciales.
Actividad 4
- Lee los datos del economista (dat/economist.csv), con indicadores de desarrollo y corrupción por países:
- HDI: Human Development Index (1: más desarrollado)
- CPI: Corruption Perception Index (10: menos corrupto)
- Crea un gráfico que:
- Cada país sea un punto
- El eje x indique CPI, el y HDI
- El color del punto indique la región
- Su tamaño sea proporcional al ranking HDI
- ¿Qué conclusiones extraes del gráfico?
economist <- read.csv("dat/economist.csv")
ggplot(economist) +
geom_point(aes(x = CPI, y = HDI, color = Region, size = HDI.Rank))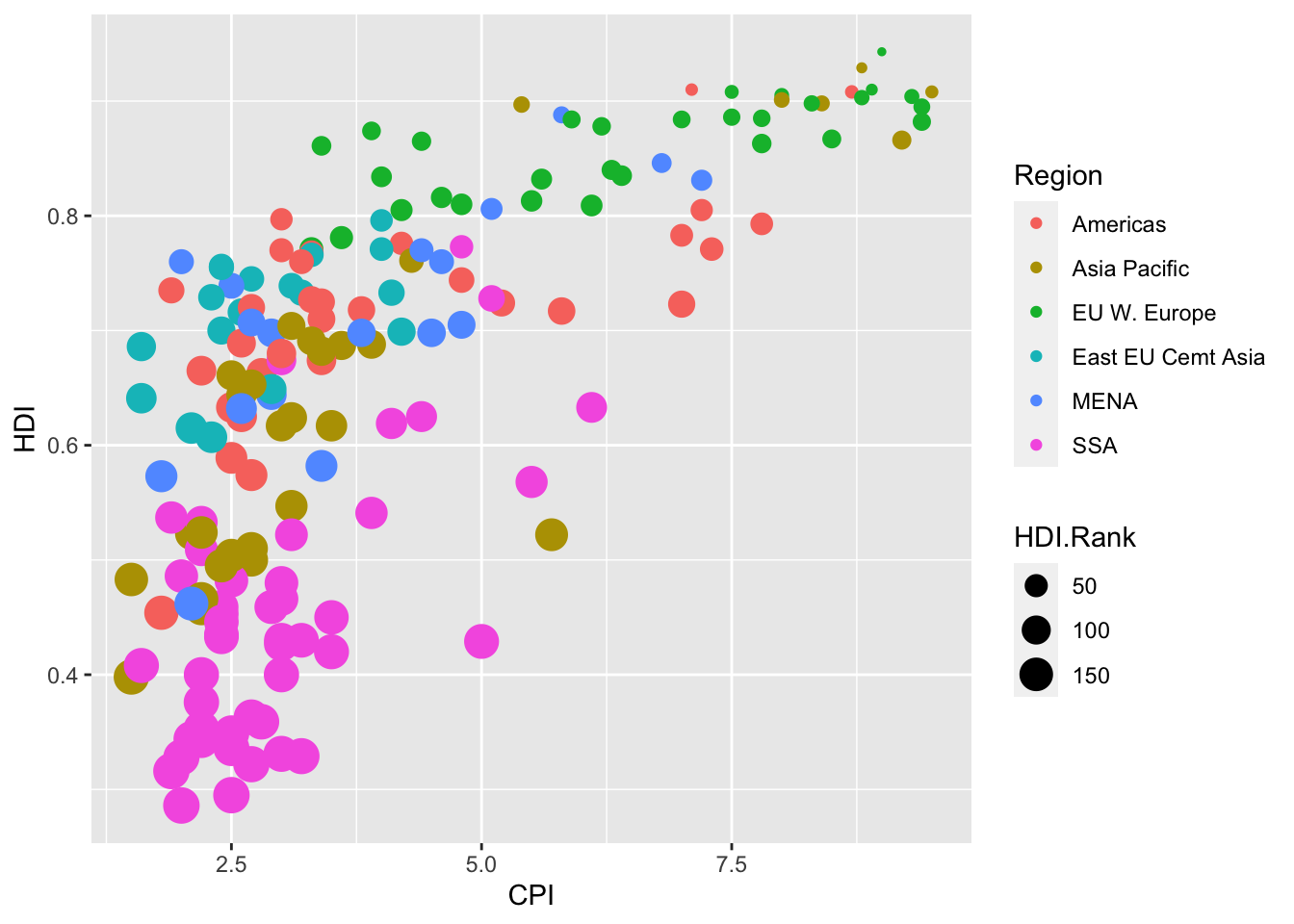
Actividad 5
Lee los datos de los resultados de las elecciones presidenciales de los Estados Unidos (dat/usa_president.csv). Puedes consultar más información sobre este dataset aquí.
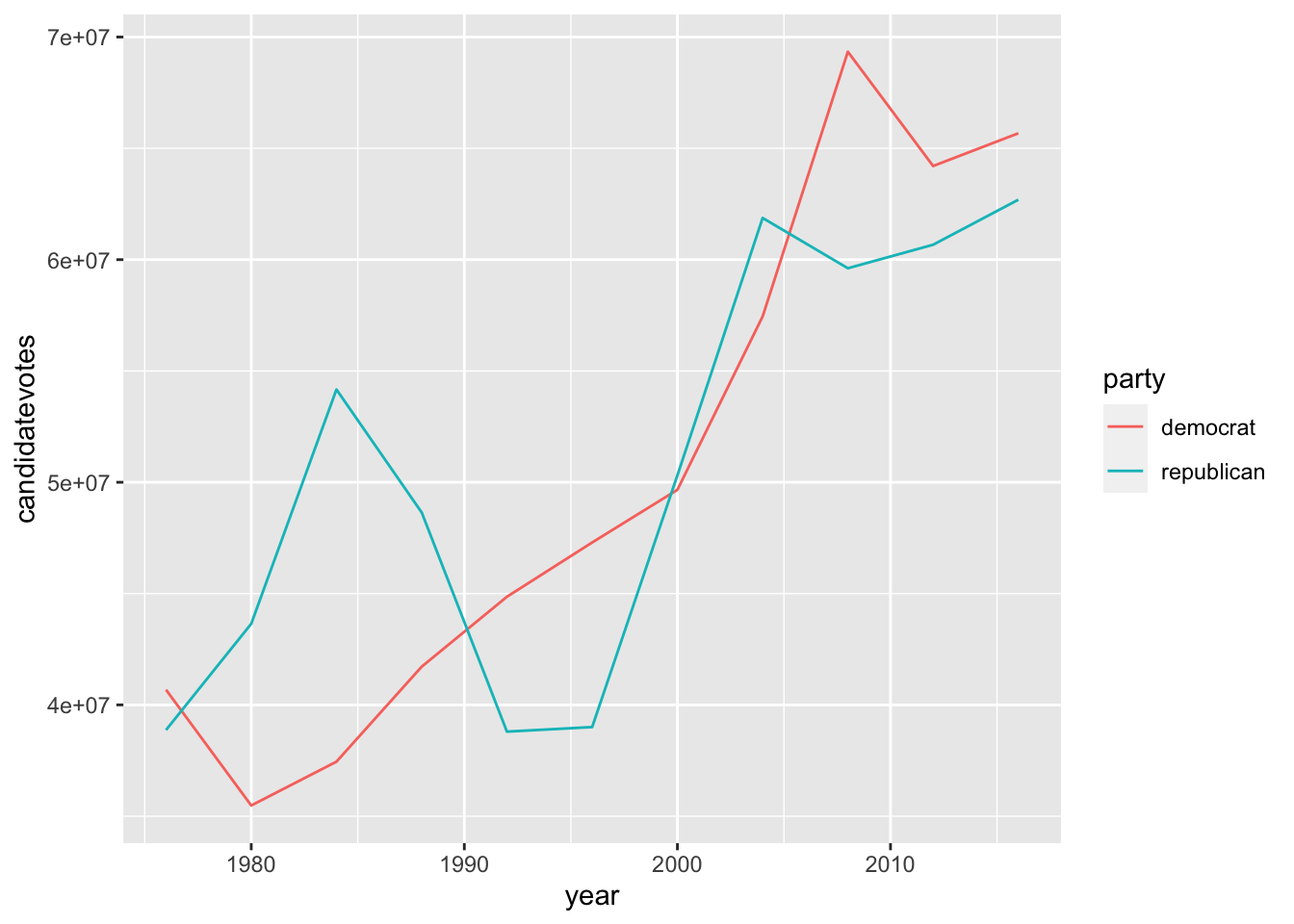
Pinta en un gráfico de líneas la evolución del número de votos a lo largo de los años del partido republicado frente al demócrata.
Ten en cuenta que tendrás que hacer una transformación de los datos antes de pintarlos. Razona en qué formato necesitas el dataframe y aplica las operaciones necesarias antes de utilizar ggplot.
# Lectura del dataset
usa_president <- read.csv("dat/usa_president.csv")
# Agrupo para los partidos de interés, por año y partido
usa_president_by_year <- usa_president %>%
filter(party %in% c("democrat", "republican")) %>%
group_by(year, party) %>%
summarise(candidatevotes = sum(candidatevotes))
# Pinto las líneas por cada partido
ggplot(usa_president_by_year) +
geom_line(aes(x = year, y = candidatevotes, color = party))