library(dplyr)
library(ggplot2)
library(palmerpenguins)Soluciones capítulo 2
Actividad 1
Rescata el gráfico que hiciste en el capítulo anterior, pero añadiendo el tercer punto aquí detallado.
- Lee los datos del economista (dat/economist.csv), con indicadores de desarrollo y corrupción por países:
- HDI: Human Development Index (1: más desarrollado)
- CPI: Corruption Perception Index (10: menos corrupto)
- Crea un gráfico que:
- Cada país sea un punto
- El eje
xindique CPI, elyHDI - El color del punto indique la región
- Su tamaño sea proporcional al ranking HDI
- Pinta una línea de tendencia que muestre la relación entre el CPI y el HDI (entre el eje
xy el ejey)
economist <- read.csv("dat/economist.csv")
# Fíjate en el mapeo "común", en ggplot, y el mapeo "específico", en geom_point
# Además, de forma opcional, he personalizado la escala de colores por una que
# distingue mejor las categorías
ggplot(economist, aes(x = CPI, y = HDI)) +
geom_point(aes(color = Region, size = HDI.Rank)) +
scale_color_brewer(palette = "Dark2") +
geom_smooth()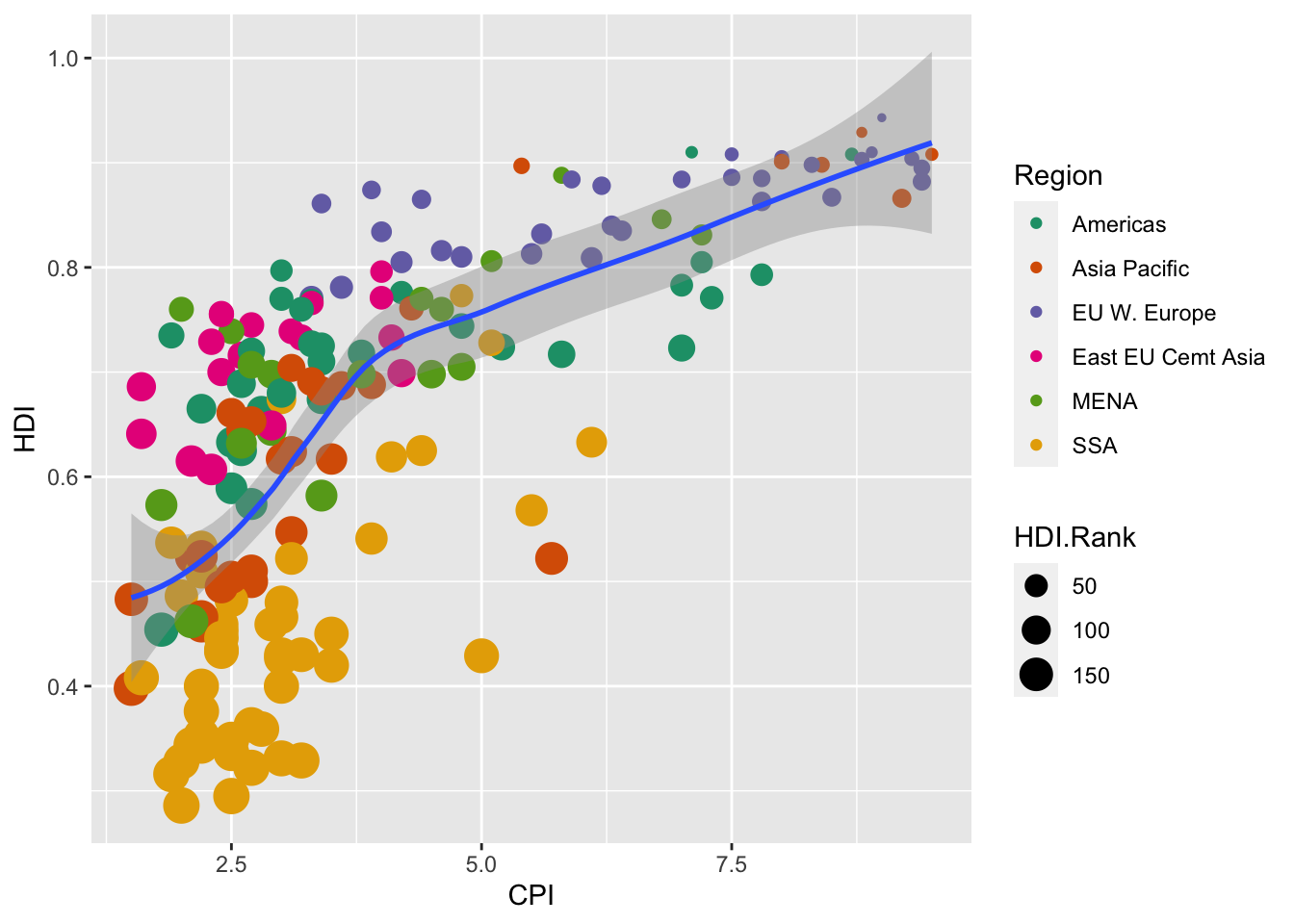
Actividad 2
Lee los datos de las elecciones presidenciales de EEUU (dat/usa_president.csv)
Quédate únicamente con los datos de las elecciones de 2016, con los resultados de los partidos demócrata y republicano, y con las filas con writein = FALSE (fe de erratas: en la versión original del capítulo viene TRUE en lugar de FALSE).
Quédate con el número de votos demócratas y republicanos para cada estado.
Pinta un gráfico de barras apiladas. Bonus: ordénalo por total de votos
usa_president <- read.csv("dat/usa_president.csv")
# Transformación previa
usa_elections <- usa_president %>%
filter(year == 2016, party %in% c("democrat", "republican"), !writein) %>%
arrange(totalvotes)
# Mi paleta de colores
# También podría utilizar códigos hexadecimales, como p.e.
# palette <- c("democrat" = "#4575b4", "republican" = "#d73027")
palette <- c("democrat" = "blue", "republican" = "red")
# Forma 1 para ordenar las barras: reorder
ggplot(usa_elections) +
geom_col(aes(y = reorder(state_po, totalvotes), x = candidatevotes, fill = party)) +
scale_fill_manual(values = palette)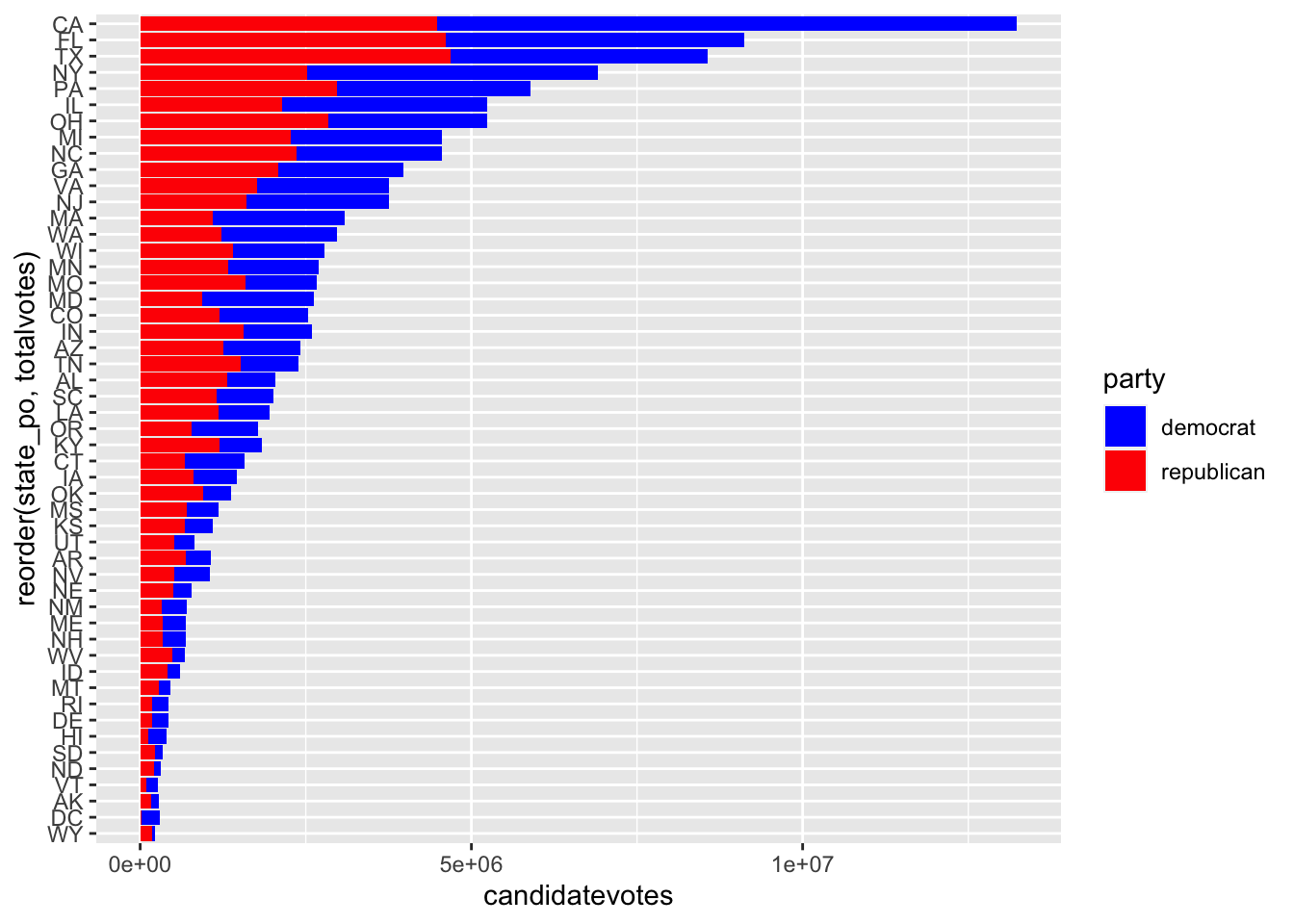
# Forma 2 para ordenar las barras: cambiar el orden del factor
states <- unique(usa_elections$state_po)
usa_elections$state_po <- factor(usa_elections$state_po, levels = states)
# Con scale_xxx_manual defino mi propia paleta de colores
ggplot(usa_elections) +
geom_col(aes(y = state_po, x = candidatevotes, fill = party)) +
scale_fill_manual(values = palette)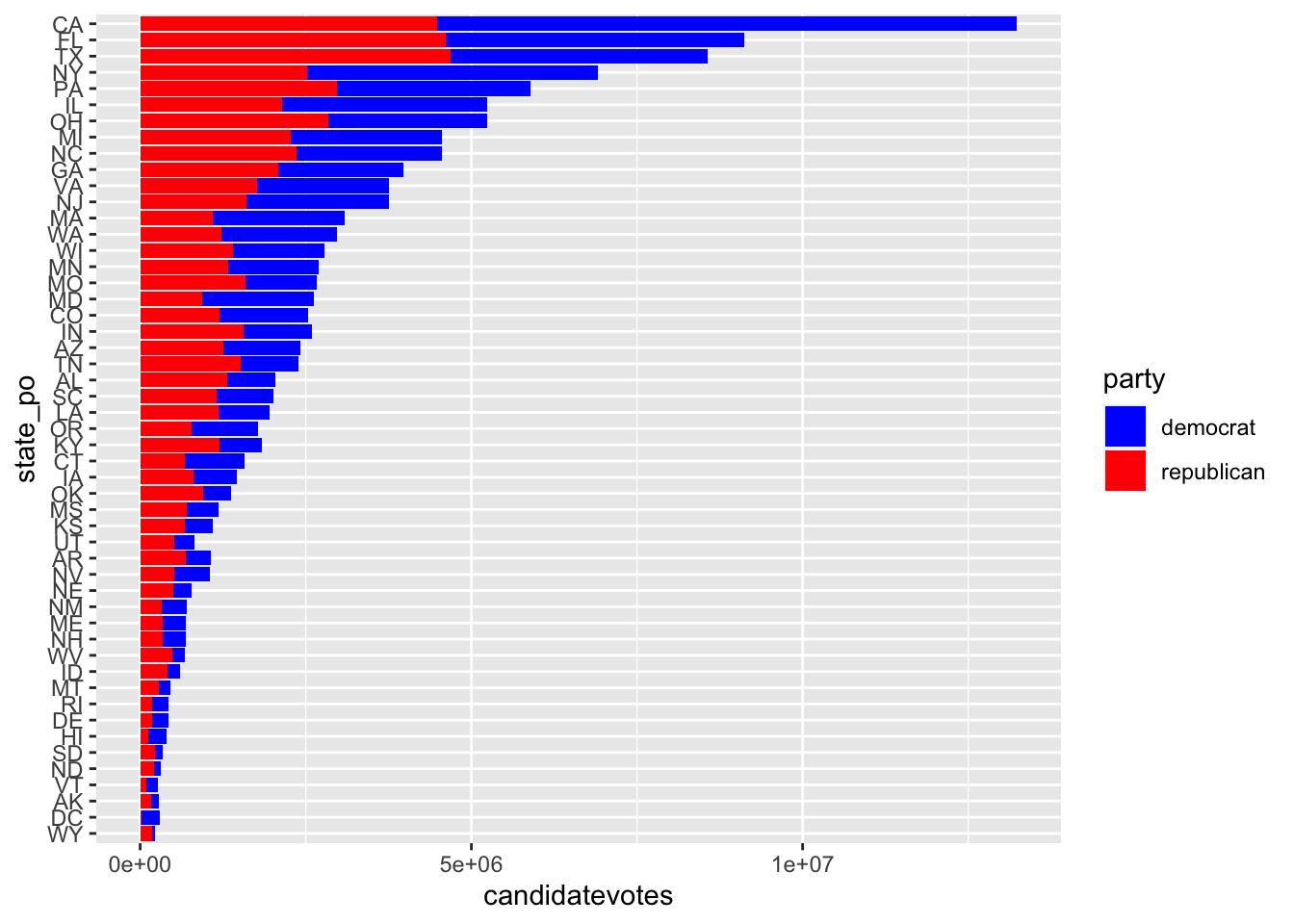
Actividad 3
Lee los datos de las elecciones presidenciales de EEUU (dat/usa_president.csv)
Como antes, quédate únicamente con los datos de las elecciones de 2016, con los resultados de los partidos demócrata y republicano, y con las filas con writein = TRUE (fe de erratas: en la versión original del capítulo viene TRUE en lugar de FALSE).
Calcula para cada estado, una columna nueva que se llame
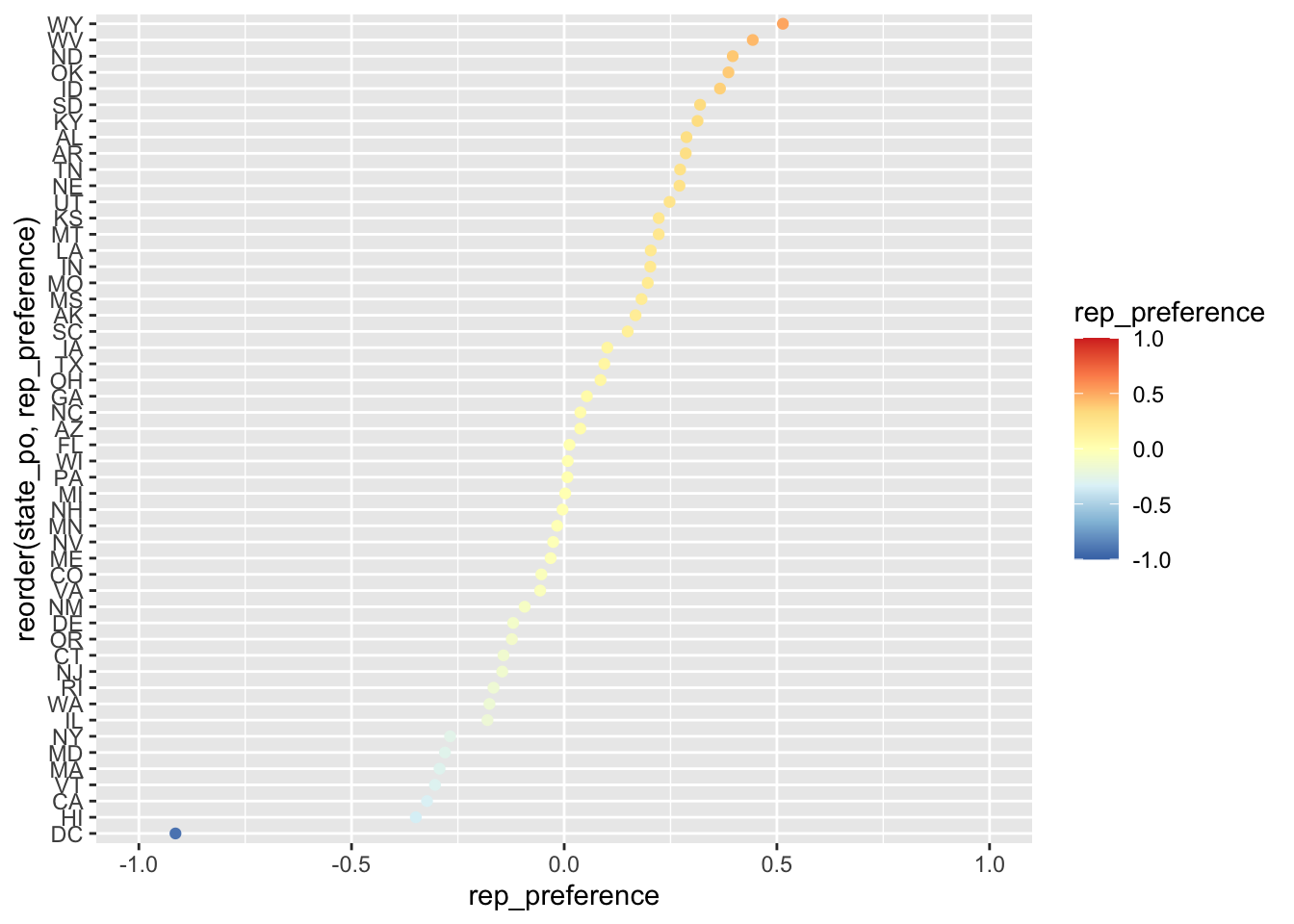
rep_preferencedefinida como(votos_republicanos / (votos_republicanos + votos_democratas) - 0.5) * 2. Esta columna tendrá valores cercanos al 0 para estados donde hubo un resultado cercano al empate, acercándose al 1 si ganaron los republicanos y acercándose al -1 si ganaron los demócratas. Nota: puede que te resulte útil separar los datos en dos datasets (votos republicanos y votos demócratas) y luego unirlos.Pinta un gráfico de puntos, en el eje
yel estado (la abreviatura de dos caracteres) y en el ejexel valor derepublican_preference. El color del punto será una escala divergente, en la que a mayor victoria republicana sea más rojo (valor más positivo), mayor victoria demócrata más azul (valor más negativo), y los cercanos al empate sean blancos o amarillos (valor más cercano al cero).Ordena los estados por
rep_preferencey centra el 0 en mitad del gráfico.Centra el cero en mitad del eje x
Centra el cero en el valor neutro de la escala de colores
# Separo los dataframes en dos: votos rep y votos dem
rep_votes <- usa_elections %>%
filter(party == "republican") %>%
select(state_po, candidatevotes)
dem_votes <- usa_elections %>%
filter(party == "democrat") %>%
select(state_po, candidatevotes)
# Los cruzo, para tener los votos de ambos en la misma fila
votes <- dem_votes %>%
inner_join(rep_votes, by = "state_po", suffix = c("_dem", "_rep")) %>%
mutate(
rep_preference = (candidatevotes_rep / (candidatevotes_rep + candidatevotes_dem) - 0.5) * 2
) %>%
arrange(rep_preference)
# Gracias a limits centro, tanto la escala de color, como la del eje x
# Con scale_xxxx_distiller transformo una escala de colorbrewer, pensada para un
# número pequeño de categorías, en una escala continua, interpolando los valores
# intermedios. Consulta la ayuda para más opciones
ggplot(votes) +
geom_point(aes(y = reorder(state_po, rep_preference), x = rep_preference, color = rep_preference)) +
scale_color_distiller(palette = "RdYlBu", limits = c(-1, 1)) +
scale_x_continuous(limits = c(-1, 1))